6 Data wrangling
6.1 Data manipulation with dplyr
dplyr คือ Package ย่อยของ tidyverse ซึ่งทำหน้าที่จัดการ Dataframe ที่ท่านนำเข้าไปใน R ให้เป็นในรูปแบบที่ท่านต้องการ
6.1.1 Basic dataframe manipulation
ในกรณีนี้จะใช้ข้อมูลตัวอย่าง iris เพื่อสาธิตการใช้ dplyr โดย iris เป็นข้อมูลของความยาวกลีบของพันธุ์ดอกไม้ต่างๆ

รูปจาก: https://www.datacamp.com/tutorial/machine-learning-in-r
df <- iris # โหลด dataframe ตัวอย่างที่ติดมากับ base R
head(df, 5)ฟังก์ชันหลักๆ ของ dplyr จะเกี่ยวข้องกับ data manipulation เป็นส่วนใหญ่ ในที่นี้จะแนะนำที่จำเป็นต้องใช้ในบทอื่น
-
glimpse()มีไว้ดูภาพรวมข้อมูล
glimpse(df)## Rows: 150
## Columns: 5
## $ Sepal.Length <dbl> 5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.9, 5.4, 4.8, 4.8, 4.3, 5.8, 5.7, 5.…
## $ Sepal.Width <dbl> 3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.4, 2.9, 3.1, 3.7, 3.4, 3.0, 3.0, 4.0, 4.4, 3.…
## $ Petal.Length <dbl> 1.4, 1.4, 1.3, 1.5, 1.4, 1.7, 1.4, 1.5, 1.4, 1.5, 1.5, 1.6, 1.4, 1.1, 1.2, 1.5, 1.…
## $ Petal.Width <dbl> 0.2, 0.2, 0.2, 0.2, 0.2, 0.4, 0.3, 0.2, 0.2, 0.1, 0.2, 0.2, 0.1, 0.1, 0.2, 0.4, 0.…
## $ Species <fct> setosa, setosa, setosa, setosa, setosa, setosa, setosa, setosa, setosa, setosa, se…-
select()เลือก column ที่ต้องการโดยใช้ตำแหน่งหรือชื่อ column ก็ได้
-
filter()กรองแถว (row) ที่ต้องการ โดยต้องระบุ ว่าต้องการข้อมูล ที่ column ไหน และต้องการกรองค่าที่เท่าไร
# เลือกแถวที่ Species = setosa, Sepal.Length = 5.4
df |>
filter(Species == "setosa" & Sepal.Length == 5.4) |> head(5)
# เลือกแถวที่ Sepal.Length = 5.1 หรือ 4.9
df |> filter(Sepal.Length == 5.1 | Sepal.Length == 4.9) |> head(10)สังเกตว่าจะเห็นเครื่องหมาย |> ซึ่งใน R ท่านจะเรียกว่า “pipe operator” เป็นสิ่งที่เป็นเอกลักษณ์ใน R ซึ่งส่งผลให้สามารถ run operation ได้ต่อๆ กัน เพื่อให้อ่านได้ง่าย
# เลือกแถวที่ Species = setosa คอลัมน์ Sepal.Length
df |>
filter(Species == "setosa") |>
select(Sepal.Length) |> head(5)
# เหมือนกับข้างบน แต่ไม่ใช้ pipe operator จะทำความเข้าใจได้ยากกว่า
select(filter(df, Species == "setosa"), Sepal.Length) |> head(5)
# ใช้แค่ base R solution จะไม่สามารถดึงออกมาเป็น dataframe ได้
df[df["Species"] == "setosa", "Sepal.Length"]## [1] 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 4.4 4.9 5.4 4.8 4.8 4.3 5.8 5.7 5.4 5.1 5.7 5.1 5.4 5.1 4.6 5.1 4.8
## [26] 5.0 5.0 5.2 5.2 4.7 4.8 5.4 5.2 5.5 4.9 5.0 5.5 4.9 4.4 5.1 5.0 4.5 4.4 5.0 5.1 4.8 5.1 4.6 5.3 5.0บรรทัดสุดท้าย สำหรับ Dataframe จะไม่สามารถดึงมาทั้งคอลัมน์ได้ ซึ่งจะต้องใช้ข้อมูลอีกแบบ (Tibble) แต่จะไม่กล่าวถึง ณ ที่นี่
Note: การ subset โดย dplyr นั้นสามารถทำใน Dataframe/Tibble เท่านั้น ไม่สามารถทำใน Matrix ได้ (ต้องใช้วิธีของ base R)
- ในส่วนการเรียงข้อมูลนั้นจะใช้ ฟังก์ชัน
arrange()
-
mutate()เป็นคำสั่งที่ใช้ในการสร้างคอลัมน์ใหม่ให้เป็นในแบบที่ต้องการได้
df |>
mutate(Sepal_mm = Sepal.Length*100) # มิลลิเมตร- ท่านสามารถจัดกลุ่มตัวแปรได้โดยใช้
group_by()โดยมักจะใช้คู่กับsummarize()ซึ่งเป็นคำสั่งที่ใช้ในการสรุปข้อมูลทั้งหมดตามที่ต้องการ หรือในdplyr1.1.0 ขึ้นไปท่านสามารถใช้.by = …ได้
df |>
group_by(Species) |> # จัดกลุ่มตาม Species
summarize(Sepal.Length = sum(Sepal.Length),
Sepal.Width = mean(Sepal.Width)) # รวมความยาวทั้งหมด และเฉลี่ยความกว้าง-
rename()สามารถใช้ในการเปลี่ยนชื่อคอลัมน์ ระวังว่าชื่อที่ต้องการจะอยู่ด้านซ้ายของเครื่องหมาย=ซึ่งไม่เหมือนคำสั่งอื่น
df |>
rename("Sepal_length" = "Sepal.Length", "Sepal_width" = "Sepal.Width") 6.1.2 Tidyselect
ในหลายๆ ฟังก์ชัน เช่น select() ,mutate(), summarize() ท่านสามารถใช้คำสั่งตัวช่วย (Selection helper) เพื่อให้การเลือกคอลัมน์ที่ต้องการเป็นไปได้สะดวกยิ่งขึ้น
| คำสั่ง | การทำงาน |
|---|---|
starts_with(), ends_width()
|
เริ่มหรือจบลงด้วยตัวอักษรที่ต้องการ |
contains() |
มีตัวอักษรที่ต้องการ |
matches() |
Regular expression |
num_range() |
ช่วงของตัวเลข เช่น 1,2,3,4, ….,10 |
where() |
คำสั่งตรวจสอบทางตรรกศาสตร์ เช่น is.numeric
|
last_col() |
คอลัมน์สุดท้าย |
everything() |
ทุกคอลัมน์ |
ในส่วนของการใช้ mutate() และ summarise() ร่วมกับคำสั่งตัวช่วยนั้น ท่านต้องใช้ภายในคำสั่ง across()
6.1.3 Joining data
หลายครั้งที่การจัดการกับข้อมูลนั้นมีที่มาจากหลายส่วน โดยคอลัมน์หลักร่วมเพียงไม่กี่คอลัมน์ ผู้วิเคราะห์สามารถรวมตารางจากหลายแห่งเข้าด้วยกันได้โดยการใช้คำสั่ง x_join เพื่อความสะดวกในการวิเคราะห์
6.1.3.1 Mutating join
Mutating join คือการรวมตารางสองตารางเข้าด้วยกันภายใต้เงื่อนไขต่างๆ ในคอลัมน์หลักที่กำหนด

ต่อไปจะใช้ตารางดังต่อไปนี้ในการแสดงตัวอย่าง
-
inner_join()รวมบรรทัดที่มีตัวแปรที่มีร่วมกันทั้งสองตาราง
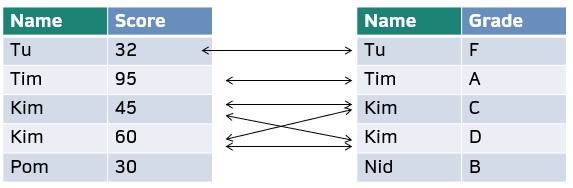
inner_join(score_df, grade_df, by = "Name")-
full_join()หรือ full outer join รวมทุกบรรทัด

full_join(score_df, grade_df, by = "Name")-
left_join()รวมบรรทัดจากตารางyที่มีตัวแปรในตารางxและคงบรรทัดในตารางxทั้งหมด

left_join(score_df, grade_df, by = "Name")-
right_join()รวมบรรทัดจากตารางxที่มีตัวแปรในตารางyและคงบรรทัดในตารางyทั้งหมด

right_join(score_df, grade_df, by = "Name")6.1.3.2 Filtering join
Filtering join คือการกรองบรรทัดในตาราง xโดยเงื่อนไขจากตาราง y

-
semi_join()กรองบรรทัดในตารางxที่มีตัวแปรในตารางy

semi_join(score_df, grade_df, by = "Name")-
anti_join()กรองบรรทัดในตารางxที่ไม่มีตัวแปรในตารางy
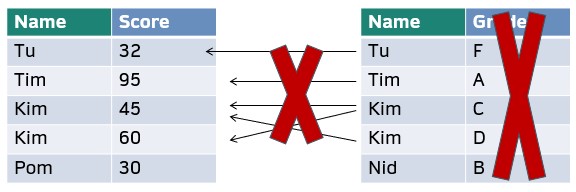
anti_join(score_df, grade_df, by = "Name")
6.2 Reshaping data with tidyr
6.2.1 Data structure
โดยปกติแล้วรูปแบบลักษณะของการบันทึกข้อมูลนั้นจะมีอยู่ 2 ลักษณะ
- Wide form เป็นลักษณะที่ง่ายต่อการบันทึก วิเคราะห์และอ่านผลเบื้องต้น โดยมีรูปแบบคือ ในแต่ละแถวนั้น จะมีข้อมูลหลักที่ไม่ซ้ำกัน (มักจะเป็นข้อมูลระบุตัวตน)
- Long form เป็นลักษณะที่ง่ายต่อการ Visualize โดยมีรูปแบบคือ สามารถมีข้อมูลหลักที่ซ้ำกันได้
ลองทำการดูที่ข้อมูล iris อีกครั้ง
head(df, 10)จะเห็นว่า ข้อมูลในแต่ละแถวนั้น คือ ดอกไม้ 1 ดอก จำนวนคอลัมน์จะมากกว่าข้อมูลแบบ Long form
df_id <- df |>
mutate(flower_id = row_number(),
.before = everything()) # สร้าง unique id ดอกไม้แต่ละดอก
head(df_id)6.2.2 Wide to long
ท่านสามารถเปลี่ยนข้อมูลจาก Wide form เป็น Long form ได้โดย package tidyr โดยใช้ฟังก์ชัน pivot_longer()
long_df <- df_id |>
pivot_longer(cols = !c(flower_id, Species),
names_to = "Metrics", values_to = "cm") # ไม่รวมคอลัมน์ Species
head(long_df,10)ซึ่งจะทำให้สามารถวิเคราะห์ข้อมูลได้สะดวกขึ้น ยกตัวอย่างถ้าเราต้องการสรุปข้อมูลชุดนี้
summary_df <- long_df |>
group_by(Species, Metrics) |>
summarize(`Median (cm)` = median(cm),`Mean (cm)` = mean(cm), `sd (cm)` = sd(cm))
summary_dfถ้าลองทำในข้อมูล Wide form
df |>
group_by(Species) |>
summarize(mean_Petal_L = mean(Petal.Length),
median_Petal_L = median(Petal.Length),
sd_Petal_L = sd(Petal.Length),
mean_Petal_W = mean(Petal.Width),
median_Petal_W = median(Petal.Width),
sd_Petal_W = sd(Petal.Width),
mean_Setal_L = mean(Sepal.Length),
median_Setal_L = median(Sepal.Length),
sd_Setal_L = sd(Sepal.Length),
mean_Setal_W = mean(Sepal.Width),
median_Setal_W = median(Sepal.Width),
sd_Setal_W = sd(Sepal.Width),
)จะเห็นว่าค่อนข้าง intensive และผิดพลาดง่าย
ปล. อย่างไรก็ตาม dplyr ในปัจจุบันมีการพัฒนาไปมาก การวิเคราะห์ ใน Wide form ก็สามารถทำได้โดยง่ายอย่างที่เคยกล่าวไปขั้นต้น ขึ้นอยู่กับว่าถนัดแบบใดมากกว่า
df |>
group_by(Species) |>
summarize(across(everything(),
list(median = median, mean = mean, sd = sd)))อีก ประเด็นสำคัญ ของข้อมูลประเภท Long form นั้นคือ สามารทำ Visualization ที่ซับซ้อนได้ดีกว่า Wide form เป็นอย่างมาก ดังตัวอย่าง Boxplot1, Boxplot2
6.2.3 Long to wide
ท่านสามารถเปลี่ยนกลับเป็น Wide form ได้เช่นกัน
wide_df <- long_df |>
pivot_wider(names_from = "Metrics", values_from = "cm")
head(wide_df, 10)หรือท่านอยากจะเปลี่ยนข้อมูลที่สรุปแล้วให้เป็น Wide form ก็เป็นได้
summary_df |>
pivot_wider(names_from = "Metrics",
values_from = c("Median (cm)" ,"Mean (cm)", "sd (cm)"))6.3 Separate and unite column with tidyr
ท่านสามารถแยกคอลัมน์ที่มีช่องว่างออกจากกันได้โดยใช้คำสั่ง separate()
ถ้าท่านต้องการรวมคอลัมน์เข้าด้วยสามารถใช้คำสั่ง unite()